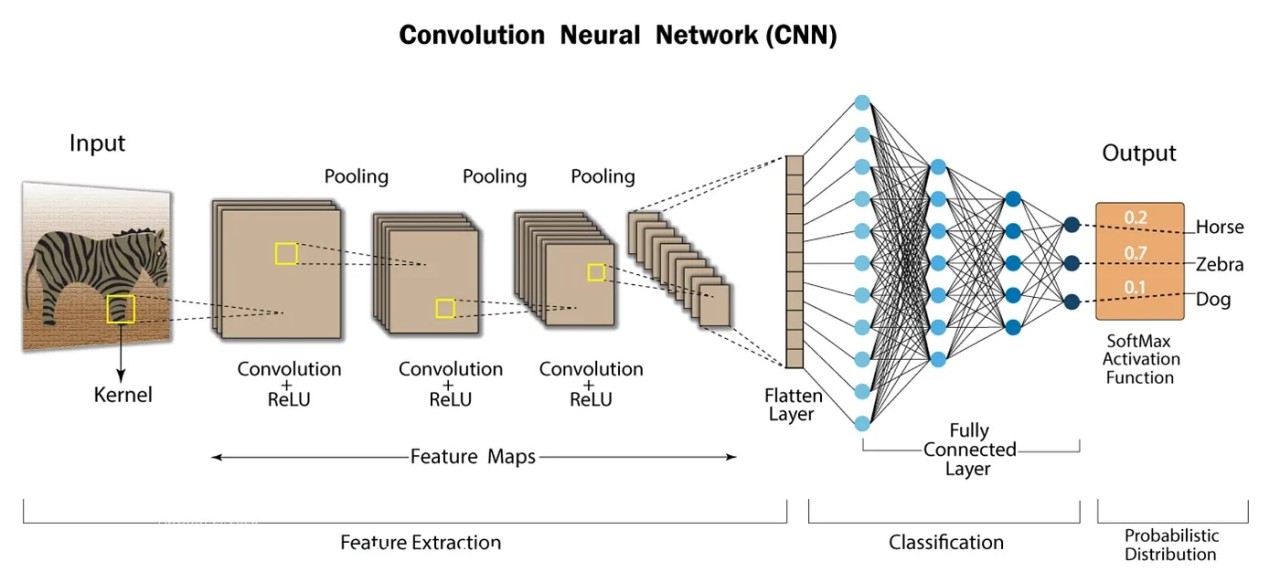
Derin Öğrenme

keras.models.Sequential(layers)
Bu fonksiyon, Keras API'sinde sıralı bir model oluşturmak için kullanılır. Sıralı model, katmanları sırayla bir araya getirerek tek bir giriş ve tek bir çıkışla basit bir yapay sinir ağı oluşturur. Bu fonksiyon çağrıldığında, boş bir sıralı model oluşturulur. Model oluşturulduktan sonra, katmanlar bu modele sırayla eklenebilir.
1. Katman Ekleme: 'add()' fonksiyonu kullanılarak katmanlar sırayla modele eklenir. Her katman, modelin ardışık bir parçası olarak belirlenir.
2. Katmanlar: Katmanlar, modelin yapı taşlarıdır ve çeşitli işlevleri gerçekleştirebilirler. Keras, farklı tipte katmanlar sağlar. Örneğin:
• 'Dense': Tam bağlı (fully connected) katman.
• 'Conv2D': 2D evrişimli (convolutional) katman.
• 'LSTM': Uzun-kısa süreli bellek (Long Short-Term Memory) katmanı.
• 'Dropout': Rastgele düşürme (random dropout) katmanı, aşırı öğrenmeyi azaltmak için kullanılır.
3. Model Derleme: Model, 'compile()' yöntemi kullanılarak derlenir. Bu adımda, modelin nasıl eğitileceği belirlenir. Kayıp fonksiyonu (loss function), optimize edici (optimizer) ve değerlendirme metrikleri belirlenir.
5. Model Eğitimi: Model, 'fit()' yöntemiyle eğitilir. Eğitim verileri modelin girişine sağlanır ve model, verilen verilere göre güncellenir.
6. Model Değerlendirme ve Tahmin: Eğitim tamamlandıktan sonra, modelin performansı 'evaluate()' fonksiyonu ile değerlendirilir ve yeni veriler üzerinde tahminler yapmak için 'predict()' fonksiyonu kullanılır.
Kısacası, 'keras.models.Sequential' fonksiyonu, Keras kütüphanesinde sıralı bir yapay sinir ağı modeli oluşturmak için kullanılır. Bu model, ardışık katmanları içerir ve her katman belirli bir işlevi gerçekleştirir. Bu şekilde, basitten karmaşığa kadar çeşitli derin öğrenme mimarileri oluşturulabilir. Şimdi ise katmanları inceleyelim.

keras.layers.Conv2D(filters, kernel_size, strides, padding, activation, input_shape)
Bu fonksiyon, evrişimli sinir ağları (Convolutional Neural Networks - CNN) içinde kullanılan bir katman türüdür. Görüntü işleme problemleri için özellikle etkilidir. Bu fonksiyonun parametreleri aşağıdaki gibidir:
• filters: Katmandaki filtre sayısı. Bu, katmanın öğreneceği özelliklerin sayısını belirler.
• kernel_size: Filtrelerin boyutu. Örneğin, '(3, 3)' bir çekirdek 3x3 boyutunda bir filtre anlamına gelir.
• strides: Evrişim adımları. Bu, filtrelerin hareket edeceği piksel sayısını belirler. Örneğin, '(2, 2)' olarak ayarlanırsa, filtre her adımda 2 piksel sağa ve 2 piksel aşağıya kayar. Varsayılan değeri '(1, 1)' dir.
• padding: Dolgu yöntemi. 'valid', dolgu yapmadan evrişim yapar; 'same', giriş boyutunu çıkış boyutuna eşitlemek için dolgu ekler. Varsayılan değeri 'valid' dir.
• activation: Aktivasyon fonksiyonu. Bu, katmanın çıktısına uygulanacak aktivasyon fonksiyonunu belirler. Varsayılan değeri 'None' dur.
• input_shape: Katmanın giriş şekli. İlk katman olarak kullanılıyorsa belirtilmesi gereklidir.
Teknik Detaylar:
• Filtreler: Conv2D katmanı, öğrenilecek filtrelerin bir kümesini içerir. Her bir filtre, özellik haritalardaki belirli özellikleri algılamak için kullanılır. Örneğin, kenar tespiti veya renk tanıma gibi.
• Çekirdek Boyutu: Filtrelerin boyutunu belirler. Örneğin 3x3 boyutunda bir çekirdek, her bir evrişim adımında 3x3 piksellik bir pencereyi işler.
• Evrişim Adımları: Filtrenin giriş üzerinde hareket edeceği adım sayısını belirler. Bu, çıkış boyutunu ve modelin karmaşıklığını etkiler.
• Dolgu (Padding): Dolgu, giriş görüntüsünün kenarlarını korumak için kullanılır. 'valid' dolgusu, giriş boyutunu azaltırken, 'same' dolgusu giriş boyutunu korur.
• Aktivasyon Fonksiyonu: Katmanın çıktısına uygulanacak aktivasyon fonksiyonunu belirler. Yaygın olarak kullanılan aktivasyon fonksiyonları arasında ReLU (Rectified Linear Unit), sigmoid ve tanh bulunur.
Conv2D katmanı, görüntü işleme problemleri için özellik çıkarma sürecinin temel bir parçasıdır. Giriş görüntüsünden özellik haritalarını üretir ve ardışık katmanlarla bu özellik karmaşıklığını artırarak daha yüksek seviyeli özelliklerin keşfedilmesine olanak tanır. Bu nedenle, CNN'lerde sıkça kullanılan ve güçlü bir bileşen olan Conv2D katmanının parametreleri ve işlevi oldukça önemlidir.

keras.layers.MaxPooling2D(pool_size, strides, padding)
Evrişimli sinir ağlarında sıklıkla kullanılan bir katman türüdür. Genellikle evrişimli katmanlarla birlikte kullanılır ve boyut azaltma amacıyla kullanılır. Bu fonksiyonun parametreleri aşağıdaki gibidir.
• pool_size: Havuzlama penceresinin boyutunu belirler. Örneğin, '(2, 2)' bir havuzlama penceresi 2x2 boyutunda olacaktır.
• strides: Havuzlama adımları. Bu parametre, havuzlama penceresinin giriş üzerinde harket edeceği piksel sayısını belirler. Örneğin, '(2, 2)' olarak ayarlanırsa, havuzlama penceresi her adımda 2 piksel sağa ve 2 piksel aşağıya kayar. Varsayılan değeri 'None' dır.
• padding: Dolgu yöntemi. 'valid', dolgu yapmadan havuzlama yapar. 'same', giriş boyutunu çıkış boyutuna eşitlemek için dolgu ekler. Varsayılan değeri 'valid' dir.
Teknik Detaylar:
• Max Pooling (Maksimum Havuzlama): MaxPooling, her bir bölgeye uygulanan bir operasyondur. Belirli bir bölgeyi alır ve bu bölgedeki en büyük değeri alarak yeni bir harita oluşturur. Bu, özelliklerin kaybını minimize ederek boyut azaltmayı sağlar.
• Havuzlama Penceresi: 'pool_size' parametresi, her bir havuzlama penceresinin boyutunu belirler. Örneğin, '(2, 2)' bir havuzlama penceresi 2x2 boyutunda olacaktır. Bu pencere, giriş görüntüsünü adım adım tarayarak maksimum değerleri alır.
• Havuzlama Adımları: 'strides' parametresi, havuzlama penceresinin giriş üzerinde hareket edeceği adım sayısını belirler. Bu, çıkış boyutunu ve modelin karmaşıklığını etkiler.
• Dolgu: Dolgu, giriş görüntünün kenarlarını korumak için kullanılır. 'valid' dolgusu, giriş boyutunu azaltırken, 'same' dolgusu giriş boyutunu korur.
MaxPooling, genellikle evrişimli katmanlarla birlikte kullanılır. Evrişimli katmanlar özellik haritalarını üretirken, MaxPooling bu özellik haritalarının boyutunu azaltarak işlem yükünü azaltır ve ayrıca ağın translasyonel invariyansını arttırır. Bu sayede, daha az sayıda parametre ve hesaplama ile daha özgün ve anlamlı özellikler elde edilebilir.

keras.layers.Flatten()
Bu fonksiyon, evrişimli sinir ağlarında kullanılan bir katman türüdür. Bu katman, evrişimli ve havuzlama katmanları tarafından oluşturulan özellik haritalarını düzleştirerek bir vektör haline getirir. Bu fonksiyonun parametresi yoktur. 2D-Vektör dönüşümü yapar.
Teknik Detaylar:
• Düzleştirme (Flattening): Flatten katmanı, gelen özellik haritalarını tek boyutlu bir vektöre dönüştürür. Örneğin, bir 2D özellik haritası (matris) girdi olarak alındığında, Flatten katmanı bu matrisi tek boyutlu bir vektöre çevirir.
• Katman Bağımsızdır: Flatten katmanı, evrişimli ve havuzlama katmanlarının çıktılarını düzleştirir, ancak bu katmanın kendisi öğrenilebilir ağırlıklara veya parametrelere sahip değildir. Yani, Flatten katmanı sadece veri yapılarını yeniden şekillendirir.
• Tam Bağlantı için Hazırlık: CNN'ler genellikle bir veya daha fazla Flatten katmanı ile sona erer. Bu, CNN katmanlarının çıkışlarının düzleştirilerek ardışık tam bağlantılı (fully connected) katmanlara (dense layers) verilmesini sağlar. Son katmandan gelen tek boyutlu vektör, genellikle sınıflandırma veya regresyon gibi türden bir çıkış katmanına (output layer) beslenir.
• Boyut Bilgisi: Flatten katmanı, özellik haritalarını düzleştirirken boyut bilgisini korur. Bu sayede, daha sonra tam bağlantılı katmanlara geçerken verinin nasıl yeniden şekillendirileceği belirlenir.

keras.layers.BatchNormalization(axis, momentum, epsilon, center, scale, beta_initializer, gamma_initializer)
Bu fonksiyon, derin sinir ağlarının eğitimini hızlandırmak ve daha iyi performans elde etmek için kullanılan bir normalleştirme tekniğidir. Bu katman, her bir mini-batch'in çıktılarını normalleştirir, bu da eğitim sırasında daha istikrarlı ve daha hızlı bir öğrenme süreci sağlar. Bu fonksiyonun parametreleri aşağıdaki gibidir.
• axis: Normalleştirme boyunca toplanacak özellik ekseninin indeksi. Varsayılan olarak son eksen seçilir.
• momentum: Ağırlıklı hareketli ortalama'nın (weighted moving average) güncellenme hızı. Varsayılan değeri 0.99'dur.
• epsilon: Sıfıra bölme hatası önleme amacıyla eklenen küçük bir sayı. Varsayılan değeri 0.001 'dir.
• center: Ortalama (mean) değerinin öğrenilebilir bir parametre olup olmayacağını belirler. Varsayılan değeri True 'dur.
• scale: Ölçek (scale) değerinin öğrenilebilir bir parametre olup olmayacağını belirler. Varsayılan değeri True' dur.
• beta_initializer: Ortalama değerinin başlangıç ağırlıklarını tanımlamak için kullanılan initializer. Varsayılan değeri 'zeros' dur.
• gamma_initializer: Ölçek değerinin başlangıç ağırlıklarını tanımlamak için kullanılan initializer. Varsayılan değeri 'ones' dır.
Teknik Detaylar:
• Normalleştirme: BatchNormalization, her mini-batch_in çıktılarını normalleştirerek aktivasyonların dağılımını stabilize eder. Bu, ağın daha hızlı ve daha istikrarlı bir şekilde öğrenmesini sağlar.
• Ağırlıklı Hareketli Ortalama (Weighted Moving Average): BatchNormalization, eğitim sırasında her bir mini-batch'in normalleştirilmiş çıktılarının ortalamasını ve varyansını hesaplar. Bu değerler, ağırlıklı hareketli ortalama ile güncellenir ve sonuçta tüm eğitim süresince bir mini-batch'in çıktılarının normalleştirilmesi için kullanılır.
• Öğrenilebilir Parametreler: BatchNormalization katmanı, ortalama ve varyans dışında öğrenilebilir parametrelere de sahip olabilir. Bu parametreler, ağın her katmanının çıktılarını daha iyi uyumlaştırmak için kullanılır.
• Stabilizasyon: BatchNormalization, ağdaki değişikliklerin stabilize edilmesine yardımcı olur. Bu, öğrenme hızını arttırırken aşırı uyum (over fitting) riskini azaltır.
BatchNormalization, derin sinir ağlarında eğitimi hızlandıran ve daha iyi performans sağlayan önemli bir tekniktir. Özellikle derin ağlarda kullanıldığında, eğitim sürecini daha istikrarlı hale getirir ve daha hızlı bir şekilde yakınsama sağlar. Bu nedenle, modern derin öğrenme mimarilerinde sıklıkla kullanılan bir katman türüdür.

keras.layers.Dropout(rate, noise_shape, seed)
Derin sinir ağlarının aşırı uyumu (overfitting) azaltmak için kullanılan bir regularizasyon tekniğidir. Bu tekniğin temel fikri, eğitim sırasında rastgele bir şekilde belirli bir oranda nöronları devre dışı bırakarak ağın karmaşıklığını azaltmaktır. Bu fonksiyonun parametreleri aşağıdaki gibidir.
• rate: Devre dışı bırakma oranı. Bu, her bir eğitim örneğinde rastgele seçilen nöronların bırakılacağı oranı belirler. Örneğin, 0.2 oranı, her eğitim örneğinde nöronların %20'sinin devre dışı bırakılacağı anlamına gelir.
• noise_shape: Dropout uygulanacak giriş boyutu ve türünü belirleyen bir tamsayı dizisi. Özellikle RNN'ler gibi bazı özel durumlar için kullanılır. Varsayılan değeri 'None' dır.
• seed: Rastgele sayı üreticisi için sabit bir başlangıç değeri. Varsayılan değeri 'None' dır.
Teknik Detaylar:
• Devre Dışı Bırakma (Dropout): Dropout, eğitim sırasında her bir mini-batch için belirtilen oranda nöronları devre dışı bırakır. Bu, her eğitim örneği için farklı bir nöron alt kümesi kullanılarak ağın genelleştirme yeteneğini arttırır.
• Regularizasyon: Dropout, ağın aşırı uyumunu azaltır. Aşırı uyum, modelin eğitim verilerine aşırı derecede uyum sağlayarak yeni verilere kötü bir şekilde genelleme yapmasına neden olan bir durumdur. Dropout, ağın öğrenme sürecini düzenleyerek aşırı uyumu azaltır ve daha iyi bir genelleme sağlar.
• Değişkenlerin Ölçeklenmesi: Dropout, eğitim sırasında nöronların devre dışı bırakılması nedeniyle çıktıların ortalama değerini azaltır. Bu nedenle, test sırasında modelin doğru sonuçlar üretebilmesi için Dropout katmanının çıktılarını ölçeklemek önemlidir. Bu genellikle Dropout katmanının eğitim ve test sırasında farklı davranmasına neden olur.
Dropout, genellikle tam bağlı katmanlar arasına yerleştirilir ve özellikle ağın karmaşıklığını azaltmak ve aşırı uyumu önlemek için kullanılır. Bu sayede, daha genelleştirilebilir ve daha iyi performans gösteren modeller elde edilir.

keras.layers.Dense(units, activation, use_bias, kernel_initializer, bias_initializer)
Tam bağlı (fully connected) katmanlar oluşturmak için kullanılan bir katman türüdür. Bu katman, her bir giriş nöronunu her bir çıkış nöronuna bağlar, böylece giriş verilerinden doğrudan çıktı üretir. Bu fonksiyonun parametreleri aşağıdaki gibidir.
• units: Katmandaki nöron sayısı. Bu, katmanın çıkış boyutunu belirler.
• activation: Aktivasyon fonksiyonu. Bu, katmanın çıktılarına uygulanacak aktivasyon fonksiyonunu belirler. Varsayılan değeri 'None' dır.
• use_bias: Bias vektörünün kullanılıp kullanılamayacağını belirler. Varsayılan değeri True 'dur.
• kernel_initializer: Ağırlıkların başlangıç değerlerini belirlemek için kullanılan initializer. Varsayılan değeri 'glorot_uniform' dur.
• bias_initializer: Bias'ın başlangıç değerlerini belirlemek için kullanılan initializer. Varsayılan değeri 'zeros' dur.
Teknik Detaylar:
• Tam Bağlantı (Fully Connected): Dense katmanı, her bir giriş nöronunu her bir çıkış nöronuna bağlar. Bu, giriş verilerinden doğrudan çıktı üretir.
• Ağırlıklar: Her bir giriş nöronu ile her bir çıkış nöronu arasında bir ağırlık bulunur. Bu ağırlıklar, başlangıçta rastgele atanır ve eğitim sürecinde güncellenir.
• Bias: Her bir çıkış nöronu için bir bias terimi vardır. Bu, çıktıların doğru bir şekilde ayarlanmasına yardımcı olur.
• Aktivasyon Fonksiyonu: Dense katmanının çıktılarına uygulanan aktivasyon fonksiyonu, modelin ve çıktıların karmaşıklığını arttırabilir. Yaygın olarak kullanılan aktivasyon fonksiyonları arasında ReLU (Rectified Linear Unit), sigmoid ve tanh bulunur.
• Initializerlar: Ağırlıkların ve bias'ın başlangıç değerleri, initializerlar kullanılarak belirlenir. Bu, ağın eğitimini ve performansını etkileyebilir.
Dense katmanı, giriş verilerini doğrudan çıktıya dönüştüren temel bir katman türüdür. Genellikle derin öğrenme modellerinde tam bağlantılı katmanlar arasında kullanılır. Bu katmanlar, modelin karmaşıklığını arttırarak daha yüksek seviyeli özelliklerin öğrenilmesine olanak tanır.
keras.layers.Conv2D ve keras.layers.Dense fonksiyonlarında parametre olarak verdiğimiz activation parametresinin hangi değerleri alabildiğini ve bu değerlerin özelliklerini inceleyelim.
• 'linear' veya None: Bu, aktivasyon fonksiyonunun kullanılmayacağını belirtir. Aktivasyon fonksiyonu olarak herhangi bir dönüşüm uygulanmaz ve çıktılar doğrudan kullanılır.
• 'relu': ReLU (Rectified Linear Unit), CNN'lerde yaygın olarak kullanılan bir aktivasyon fonksiyonudur. ReLU, negatif giriş değerlerini sıfıra dönüştürürken pozitif değerleri doğrudan geçirir. Bu, ağın öğrenme sürecini hızlandırır ve aşırı uyumu azaltır.
• 'sigmoid': Sigmoid aktivasyon fonksiyonu, çıktıları [0, 1] aralığına sıkıştırır. Bu, çıktıları olasılık değerleri olarak yorumlanabilecek bir formata getirir. Sıklıkla ikili sınıflandırma problemlerinde kullanılır.
• 'tanh': Tanh aktivasyon fonksiyonu, çıktıları [-1, 1] aralığına sıkıştırır. Sıfıra yakın girişlerde lineer davranırken, diğer bölgelerde non-lineer davranış sergiler. Bu, ağın öğrenme sürecini arttırır ve çıktıların dağılımını merkezlemeye yardımcı olur.
• 'softmax': Softmax aktivasyon fonksiyonu, çıktıları bir olasılık dağılımı olarak yorumlanabilir bir şekilde normalize eder. Özellikle çoklu sınıflandırma problemlerinde kullanılır.
Bu aktivasyon fonksiyonlarının seçimi, ağın yapısına ve çözmek istediği problemin doğasına bağlıdır. ReLU genellikle gizli katmanlarda tercih edilirken, sigmoid ve softmax genellikle çıkış katmanlarında kullanılır. Tanh ise daha eski modellerde yaygın olarak kullanılırken, ReLU'nun yaygınlaşmasıyla birlikte daha az kullanılmaktadır.
keras.layers.Dense() fonksiyonunda ki kernel_initializer ve bias_initializer parametrelerinin alabildiği değerleri ve bu değerlerin özelliklerini inceleyelim.
'kernel_initializer' parametresi, ağırlık (weight) matrisinin başlangıç değerlerini belirlemek için kullanılır. Bu parametre, ağırlık matrisinin nasıl başlatılacağını kontrol etmemizi sağlar ve modelin eğitim sürecini etkiler.
'bias_initializer' parametresi ise, bias terimlerinin (sapma değerlerinin) başlangıç değerlerini belirlemek için kullanılır. Bu parametre, bias terimlerinin nasıl başlatılacağını kontrol etmemizi sağlar. Bias terimleri, her bir çıktı nöronu için eklenen sabir bir değerdir ve ağın daha esnek olmasını sağlar.
• 'zeros': Tüm ağırlıkların/bias değerlerini sıfır olarak başlatır. Bu, ağın başlangıçta çok düşük bir kapasiteyle başlamasına neden olabilir ve öğrenme sürecini yavaşlatabilir. Ancak, bazı durumlarda kullanışlı olabilir, özellikle ağın belirli bir davranışı öğrenmesini istemiyorsak.
• 'ones': Tüm ağırlık/bias değerlerini bir olarak başlatır. Bu, ağın başlangıçta yüksek bir kapasiteyle başlamasına neden olabilir ve öğrenme sürecini hızlandırabilir. Ancak, genellikle kullanılmaz, çünkü rastgele başlatılmış ağırlıklar daha iyi sonuçlar verir.
• 'uniform': Belirli bir aralıkta rastgele dağıtılmış değerlerle ağırlıkları/bias değerlerini başlatır. Bu, ağırlıkları/biasları rastgele bir şekilde başlatır ve öğrenmenin daha etkili olmasına yardımcı olur. Ancak, uniform dağıtımın verimliliği problem ve veri setine bağlı olabilir.
• 'glorot_uniform' veya 'xavier_uniform': Xavier initializer olarak da bilinir. Bu, ağırlıkları/biasları belirli bir uniform dağılım aralığında başlatır, ancak bu aralık giriş ve çıkış nöron sayısına bağlı olarak dinamik olarak ayarlanır. Bu, daha iyi bir öğrenme oranı ve daha hızlı konverjans sağlayabilir.
• 'glorot_normal' veya 'xavier_normal': Xavier initializer'ın normal dağılım versiyonudur. Ağırlıkları belirli bir normal dağılıma göre başlatır ve genellikle daha iyi performans sağlar.
• 'he_uniform': He initializer olarak da bilinir. Bu, ağırlıkları belirli bir uniform dağılım aralığında başlatır, ancak bu aralık giriş ve nöron sayısına bağlı olarak ayarlanır. Özellikle ReLU aktivasyon fonksiyonu ile birlikte kullanıldığında etikilidir.
• 'he_normal': He initializer'ın normal dağılım versiyonudur. Ağırlıkları/biasları belirli bir normal dağılıma göre başlatır ve genellikle daha iyi performans sağlar.
Initializer seçimi, modelimizin performansını ve eğitim sürecini etkileyebilir. Başlangıçta rastgele başlatılmış ağırlıklar/biaslar genellikle iyi sonuçlar verir ve ağırlık/bias initializasyonunda yaygın olarak kullanılırlar. Bununla birlikte, belirli bir problem veya model için daha uygun olan özel initializer'ları seçmek de önemlidir.
Trex Runner Oyununu Görüntü İşleme Modeline Oynatalım.
Şimdi ise yukarıda öğrendiklerimizi kullanarak çeşitli derin öğrenme mimarileri kuralım ve trex runner oyunundan topladığımız veriler ile yapay zeka modelimizi kuralım. Projenin kaynak kodlarını github hesabımda paylaşıyor olacağım. Veri toplama ve etiketleme süreci ile kafanızda soru işaretleri oluşursa benimle iletişime geçebilirsiniz. Böylece Veri toplama ve hazırlığı sürecini de yazıma ekleyebilirim.
Öncelikle kullanacağımız fonksiyonları import edelim.
import os
import glob
import numpy as np
from PIL import Image
import seaborn as sns
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import LabelEncoder, OneHotEncoder
from keras.models import Sequential
from keras.layers import Dense, Dropout, Flatten, Conv2D, MaxPooling2D, BatchNormalization, Input
from tensorflow.keras.preprocessing.image import ImageDataGenerator
1. Mimari Kodları:
def architecture1(self):
model = Sequential()
model.add(Conv2D(filters=32, kernel_size=(3, 3), activation='relu', input_shape=(self.width, self.height, 1)))
model.add(Conv2D(filters=32, kernel_size=(3, 3), activation='relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(rate=0.25))
model.add(Flatten())
model.add(Dense(units=128, activation='relu'))
model.add(Dropout(rate=0.4))
model.add(Dense(units=3, activation='softmax'))
return model
1. Mimari Özeti:

2. Mimari Kodları:
def architecture2(self):
model = Sequential()
#block 1
model.add(Input(shape=(self.width, self.height, 1)))
model.add(Conv2D(filters=32, kernel_size=(3, 3), activation='relu', kernel_initializer='he_uniform', padding='same'))
model.add(Conv2D(filters=32, kernel_size=(3, 3), activation='relu', kernel_initializer='he_uniform', padding='same'))
model.add(MaxPooling2D(pool_size=(2, 2)))
#block 2
model.add(Conv2D(filters=64, kernel_size=(3, 3), activation='relu', kernel_initializer='he_uniform', padding='same'))
model.add(Conv2D(filters=64, kernel_size=(3, 3), activation='relu', kernel_initializer='he_uniform', padding='same'))
model.add(MaxPooling2D(pool_size=(2, 2)))
#block 3
model.add(Conv2D(filters=128, kernel_size=(3, 3), activation='relu', kernel_initializer='he_uniform', padding='same'))
model.add(Conv2D(filters=128, kernel_size=(3, 3), activation='relu', kernel_initializer='he_uniform', padding='same'))
model.add(MaxPooling2D(pool_size=(2, 2)))
# Flatten layer
model.add(Flatten())
# Hidden layers
model.add(Dense(units=128, activation='relu', kernel_initializer='he_uniform'))
model.add(Dense(units=3, activation='softmax'))
return model
2. Mimari Özeti:

3. Mimari Kodları:
def architecture3(self):
model = Sequential()
#block 1
model.add(Conv2D(filters=32, kernel_size=(3, 3), activation='relu', kernel_initializer='he_uniform', padding='same', input_shape=(self.width, self.height, 1)))
model.add(BatchNormalization())
model.add(Conv2D(filters=32, kernel_size=(3, 3), activation='relu', kernel_initializer='he_uniform', padding='same'))
model.add(BatchNormalization())
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(rate=0.2))
#block 2
model.add(Conv2D(filters=64, kernel_size=(3, 3), activation='relu', kernel_initializer='he_uniform', padding='same'))
model.add(BatchNormalization())
model.add(Conv2D(filters=64, kernel_size=(3, 3), activation='relu', kernel_initializer='he_uniform', padding='same'))
model.add(BatchNormalization())
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(rate=0.3))
#block 3
model.add(Conv2D(filters=128, kernel_size=(3, 3), activation='relu', kernel_initializer='he_uniform', padding='same'))
model.add(BatchNormalization())
model.add(Conv2D(filters=128, kernel_size=(3, 3), activation='relu', kernel_initializer='he_uniform', padding='same'))
model.add(BatchNormalization())
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(rate=0.4))
# Flatten layer
model.add(Flatten())
# Hidden layers
model.add(Dense(units=128, activation='relu', kernel_initializer='he_uniform'))
model.add(BatchNormalization())
model.add(Dropout(rate=0.5))
model.add(Dense(units=3, activation='softmax'))
return model
3. Mimari Özeti:

Yukarıdaki 3 farklı mimariyi eğittiğimizde ise değerlendirme sonucu aşağıdaki gibi oluyor.
{
'Model 1': {
'Train Accuracy Score': 0.9678714871406555, 'Train Loss Score': 0.09956320375204086,
'Test Accuracy Score': 0.9397590160369873, 'Test Loss Score': 1.0544294118881226},
'Model 2': {
'Train Accuracy Score': 0.9759036302566528, 'Train Loss Score': 0.04812003672122955,
'Test Accuracy Score': 0.9397590160369873, 'Test Loss Score': 0.4074130356311798},
'Model 3': {
'Train Accuracy Score': 0.36947789788246155, 'Train Loss Score': 1.8127636909484863,
'Test Accuracy Score': 0.3132530152797699, 'Test Loss Score': 1.6871029138565063}
}
Görüldüğü üzere en iyi sonucu mimari 2'den elde ettik. Bu şekilde, bir problemi yapay zeka ile çözmek için birden fazla mimari kurabilir ve her mimaride birbirinden farklı parametreleri test ederek en iyi sonucu bulabilirsiniz. Eğitim doğruluk değerlerinin, test doğruluk değerlerinden fazla olması, modelin overfitting yaptığını gösterir. Bunun önüne geçmek için veri çoğaltma yapabilir veya modeli eğitirken belirlediğimiz epoch, batch_size parametrelerinde değişiklik yapabilirsiniz.